Open Source is Missing Out on Microservices - Kubernetes is the Solution
How we use Kubernetes and Docker to overcome installation difficulties and distribute our open source microservices project


Microservice architecture has been a buzzword for a while now, and although the idea has some drawbacks, it’s certainly seen its share of success in the world of enterprise architecture. Where it’s been notably absent, however, is in open source — although open source is everywhere in microservices tooling, there’s very few projects that actually follow the pattern themselves. This is a shame, as in my view the benefits of microservice architecture are even more significant for open source teams than those within a commercial organization.
The most significant roadblock to seeing more microservices-based open source projects, in my mind at least, is the difficulty of installation. Documenting and supporting the installation process of even a single, monolithic server — and hence catering for all the various operating systems and environmental corner cases that users might have — is already pretty difficult. With this in mind, I can understand why overworked and under-appreciated open source maintainers don’t want to multiply this effort by the number of microservices they create.
Fortunately the landscape is changing, and deployment is getting much easier. Docker has made it easy for software to be bundled and distributed — compare the four page official guide for running Drupal to the docker version, which essentially boils down to “run docker-compose up”. With Kubernetes ascending as the de facto standard for orchestrating containers, we’re at a point where we can define entire networks of microservices on Github as text, and install them with a single command on any infrastructure. The time for open source microservices has arrived.

What Open Source Has To Gain from Microservices
Naturally there’s a lot of open source projects — libraries, frameworks, mobile apps — that aren’t about to be turned into microservices. I’m thinking mainly of big, server-based projects with rich plugin ecosystems, like Wordpress, Jenkins, and MediaWiki.
Plugins in this style of application are usually installed by integrating them directly with the code of a central monolith, which throws up a number of problems. Difficult installation processes, plugins that are incompatible with each other and inability to upgrade the core technology because it might break customisations abound, and naturally contributing to the ecosystems of these projects requires a developer to already know the language that the core is written in.
So what if these extensions were implemented as microservices?
- Plugins wouldn’t be able to abuse private APIs and create incompatibilities
- Fault isolation would reduce the risk of a bad plugin bringing down the whole system
- Language-agnostic APIs (i.e. HTTP-based) could enable extensions in any language and lower the barrier to contribution
- As long as the HTTP API remained compatible, the core system could be upgraded completely independently to the extensions
Naturally not all plugins — particularly those that modify the UI — are going to fit into this model, but there’s no reason that extensions to logic couldn’t be pulled out into their own service and communicate via HTTP instead of directly. Even aside from plugins, just dividing the core into microservices has its own set of open source-specific advantages too:
- Contributions can be made to a single service without having to understand the whole system, making it easier for new contributors to jump in
- Strong module boundaries between microservices make it easier for progress to be made without constant communication and review across the entire team — a problem that’s even more acute in open source than it is for big, distributed teams in enterprises.
It’s no silver bullet, and there’s plenty to be wary of, but there’s a great deal to be gained too.
How Microservices Works for Us
For the past year or so we’ve been working on Magda — a new, open source data platform to power the next generation of data.gov.au, currently in alpha.
Data.gov.au has thus far been powered by the venerable CKAN — another example of an open source monolith with a big plugin ecosystem, with the same extensible-monolith problems I described above. In envisioning a system that improves on data.gov.au’s heavily-extended CKAN installation, we set out to push the envelope in terms of not just providing the ability to extend the platform (which CKAN already does an admirable job of), but also the ease of installing extensions, and maintaining the resulting system.
As a team, our previous open-source experience has been in developing TerriaJS, a library for building web-based data maps (check it out on nationalmap.gov.au). TerriaJS is intended to be built on top of, but unfortunately extending it is a big undertaking — it requires a developer to not only already be familiar with front-end development, but learn our APIs, patterns and philosophies too.
We wanted to do better with Magda, allowing people to develop extensions in whatever technology best suited their skills and their problem, and coding against a simple, well-defined, and stable set of APIs that couldn’t be bypassed or abused. Our answer: microservices!
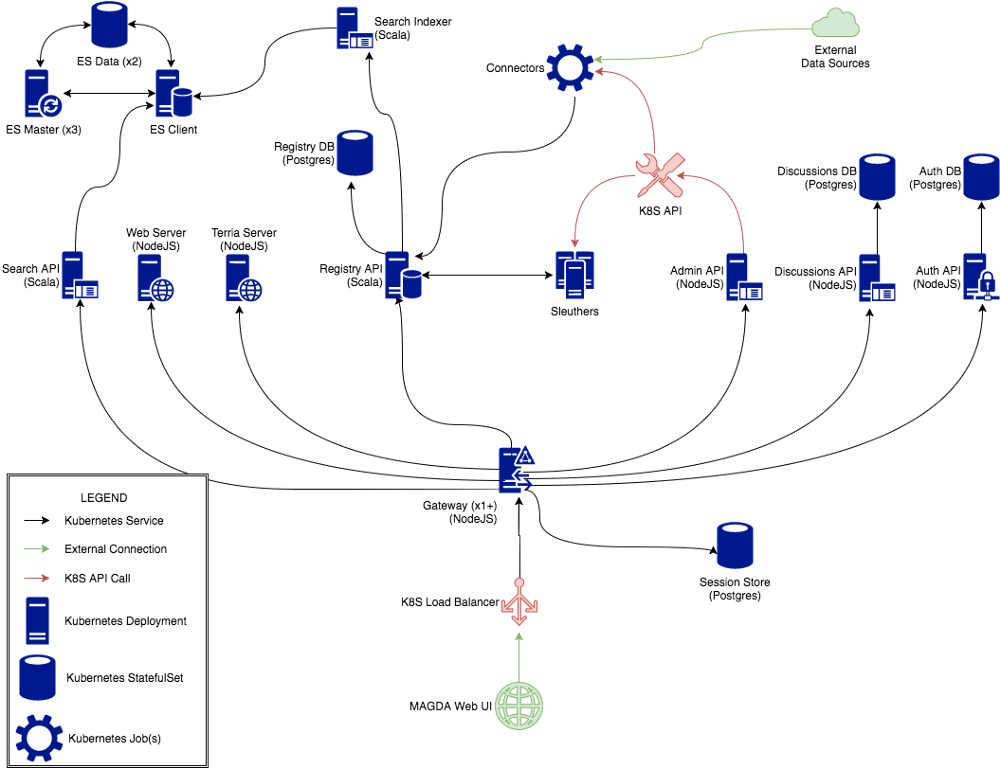
Magda is made up of a number of small, mostly self-contained services — search, administration, authorization, discussions, a web server and an API gateway. At the center is the registry, an unopinionated database that stores records as sets of “aspects” — various views of a record, each of which conform to their own JSON schema.
Upon being created, services can subscribe to events (e.g. a new record being created), as well as write their own data in the registry, either by creating their own aspect, or by patching an existing one.
An example of how this facilitates extension is what we call “sleuthers” — these are microservices that sit on the network and listen for records to be added or modified. When this happens they’ll perform some kind of operation and write the result back to the registry. For instance, we have a sleuther that:
- Checks whether URLs linked to by datasets actually work
- Writes the result back to its own aspect (which is read by the UI)
- Patches a corresponding quality rating into a shared “quality” aspect
… this in turn is listened to by the search indexer, which averages out quality ratings and uses them to inform search ordering.
To be compatible with Magda, a sleuther needs only to make an HTTP call to register itself, expose an HTTP interface that can accept webhooks, then make another HTTP call to record its results — nearly any programming language I can think of is capable of this (sorry QBasic).
The sleuther also:
- Can’t hit private APIs
- Can be updated independently of the registry (and vice versa)
- Can’t take down the whole system unless it somehow manages to kill all of the machines hosting the system, and
- Can be removed easily — just shut down the service and remove its webhook registration.
Gluing It All Together: Kubernetes and Helm
Naturally this is impractical in a world where every node on the network requires a new VM to be manually provisioned, dependencies set up, an application installed, network configured etc. Luckily, times are changing.

With Docker and Kubernetes, we can write down our entire system — runtimes, databases, configuration, storage, autoscaling, load balancing, networking and all — as readable, source-controllable text files that can be used to build the system from scratch, automatically, reproducibly and on any cloud or on premises.
Helm then allows us to turn these files into templates, providing specific customizations for various contexts, and track those customizations too. For instance, you might want to provision different storage depending on whether the system is running on Google Cloud or AWS, or run only a single database server in development.
The result is that whether running locally (with minikube), on a cloud provider or on premises, a complex system can be installed with a simple helm install --values customization.yaml. Get something wrong? Fix it and run helm upgrade <installation-name> --values customization.yaml — Helm and Kubernetes will figure out what’s changed and update your cluster automatically.
Breaking the Fourth Wall
Where this gets truly crazy is that using the Kubernetes API, you can also modify your cluster’s configuration from within the cluster itself!

We’re currently adding functionality to Magda that allows an administrator to add services to their installation without having to know what Kubernetes even is.
A key feature of Magda is federation — it’s able to connect to external data sources and crawl their contents, bringing the metadata into its own registry and indexing it for search. Naturally, these connectors are implemented as microservices.
Through our admin interface, a user simply needs to provide id of an appropriate docker image and the configuration it needs — then through the Kubernetes API, we can create a new container, run the desired image, pass the right configuration and clean up once its finished. Because Kubernetes uses a declarative model for configuration, we easily roll back to the previous version in the event of a problem, or even pull the new config out so that this cluster can be exactly replicated elsewhere.
We’re even able to integrate with Kubernetes’ jobs API to provide a dashboard for what’s currently being crawled. In this way, we’re able to get a package manager for free from Docker, and a distributed job scheduler for free from Kubernetes.
Kubernetes is our Runtime
Creating this kind of hard dependency on a technology does lock us in to some extent, but given that Kubernetes is an open-source, vendor-agnostic and well-supported technology, we’re happy to take the risk given what we gain. Effectively, what PHP is to Wordpress and the JVM is to Jenkins, Kubernetes is to Magda.

Kubernetes is still new and immature in a lot of ways (many features we use are still in beta, for instance), but in the year or so we’ve been using it we’ve seen a massive amount of momentum grow behind it, and we only expect this to continue.
I don’t think we’ll be seeing the open source monoliths I picked on in this post moving to microservices any time soon, but for new projects that aspire to similar ambitions, it’s a very compelling proposition. The confluence of Docker, Kubernetes and Helm makes distributing, installing and maintaining even single-tier applications so much easier than it ever was before, and once these technologies are in place, the leap from monoliths to microservices in open source is looking smaller than ever.